

☆
1
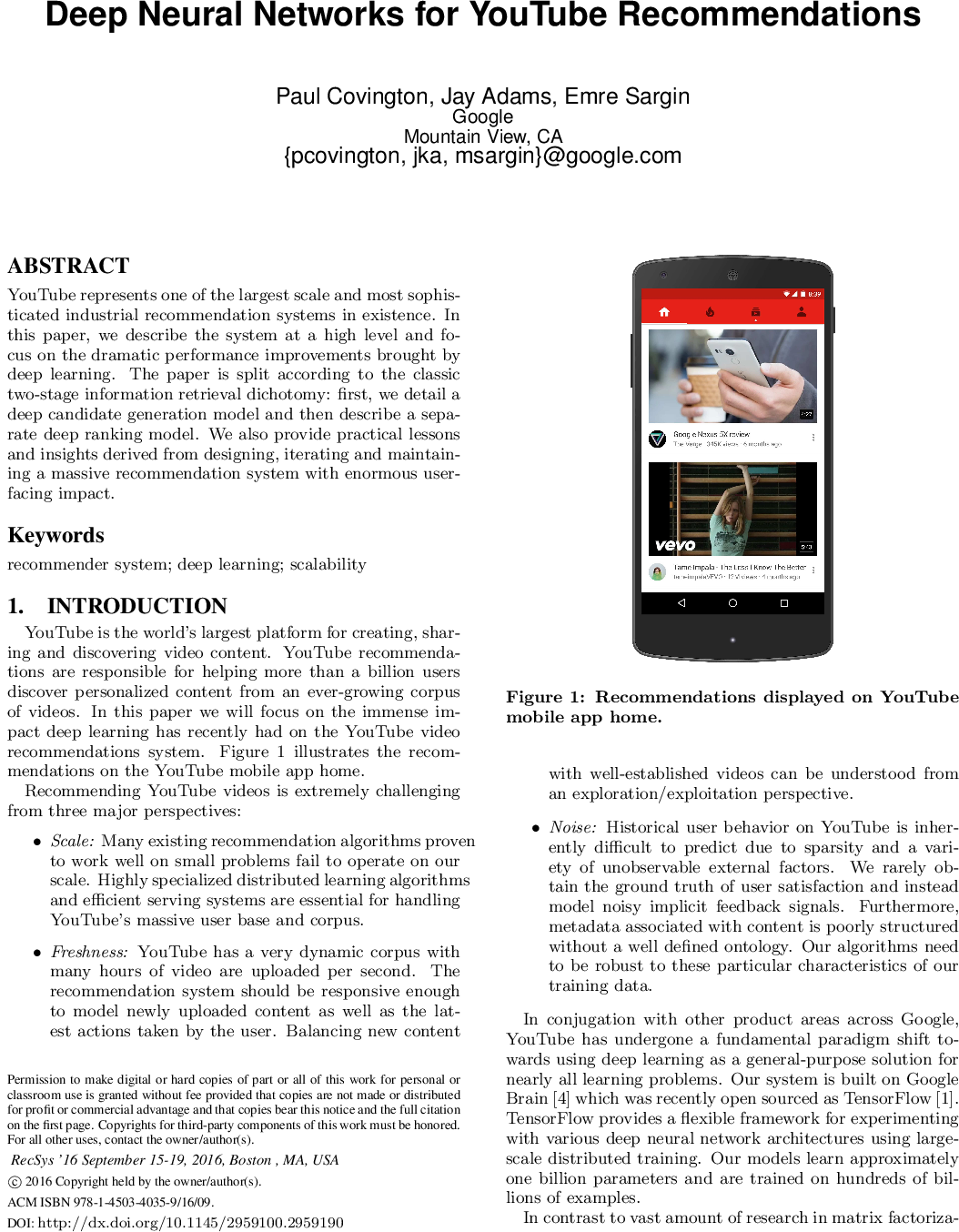
Authors:
Paul Covington,
Jay Adams,
Emre Sargin
Liked by: Alt-Tab
Domains: Machine Learning, Recommendation
Tags: deep learning, recommendation system
Liked by: Alt-Tab
Domains: Machine Learning, Recommendation
Tags: deep learning, recommendation system
Uploaded by:
Alt-Tab
Upload date: 2018-10-31 10:47:56
Upload date: 2018-10-31 10:47:56
Comments:
Edited by Alt-Tab at 2018-10-31 16:12:40